2 Years
So as a follow up to the 1 Year stats post, here are a bunch of stats to celebrate 2 years of efaller.com. These are the stats from the last year of web visitors to the site (which does not include RSS readers).
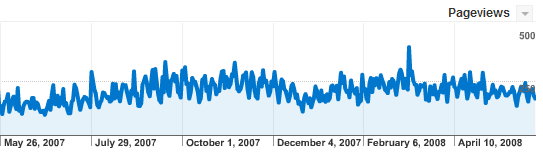
Daily Pageviews
There were an average of 225 pageviews per day, a 12.5% growth YOY but still not enough to make money with AdSense :(.
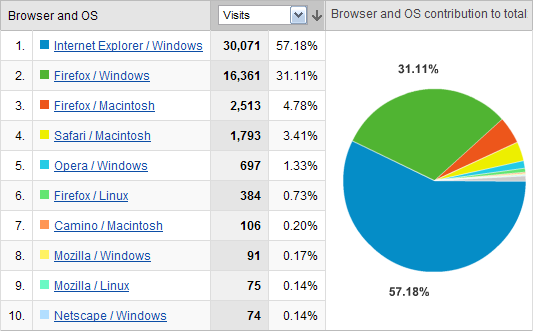
Browser/OS Combinations
This year IE/Windows increased its share from 54% to 57%, Firefox/Windows increased from 30% to 31%, and Firefox/Mac increased from 4.1% to 4.8%. The biggest loser was Safari/Mac which fell from 7.3% to 3.4%. Linux (all browsers) stayed pretty constant at 0.87%.
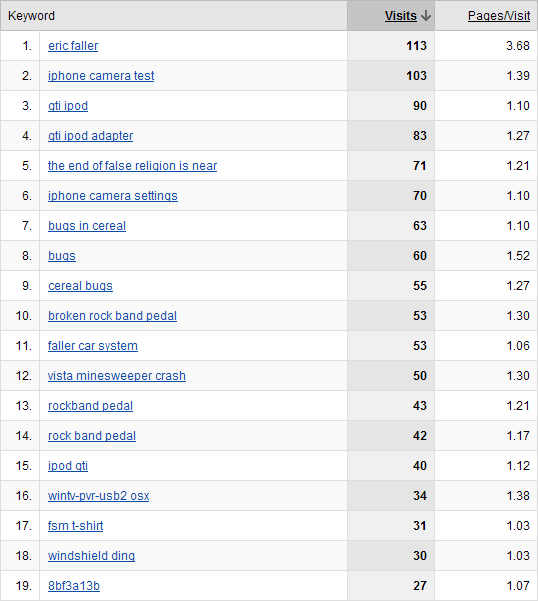
Search Engine Keyword Hits
In this year's search engine results I was finally able to overcome the end of false religion is near with searches for my name. The results also reveal growing interest in the zeitgeist with iPhones, GTI iPods, and broken Rock Band drum pedals.
Bugs, cereal bugs and bugs in cereal also made a big showing, and if combined would beat out searches for me.
Another interesting hit is 8bf3a13b - people are still searching for this, and I'm surprised that the answer hasn't been widely posted on the web yet.
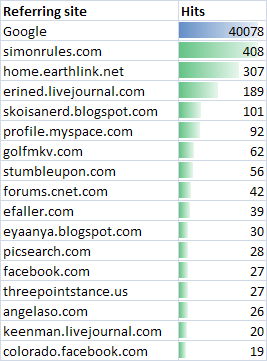
Referrers
In the referring sites competition Google dominated all comers, but Simon made a strong second place showing:
1 Year
One year ago I created this web site with the goals of creating something that might be interesting enough to read and to take over the #1 Google search result for my name. I'm not unbiased enough to comment on the first goal, but I can gauge the success of the second:
- #1 in Google search results - Check
- #1 in Yahoo search results - Check
- #1 in Live.com search results - Check
In fact, as an added bonus due to some blog posts and a magazine article I wrote for work, now 9 out of the top 10 and 43 out of the top 50 Google search results for my name are related to me. Sweet. I don't think I have to worry that somebody searching for me will find the wrong person any more.
It's also interesting to check out the Analytics stats for the past year (which, somewhat significantly, do not include RSS readers):
Daily pageviews:
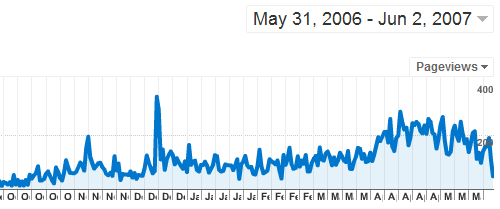
Thoughts:
- 200 pageviews per day? Not enough for AdSense 🙁 (not that I would anyway)
Hits by Browser/OS combination:
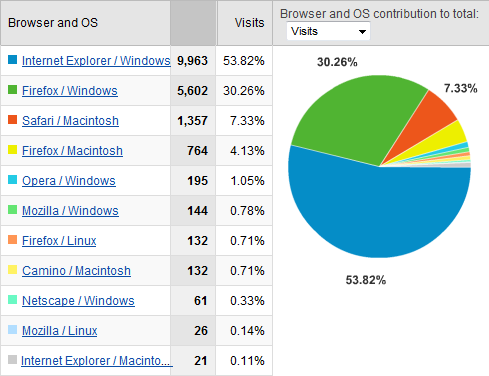
Thoughts:
- Since 90% of the hits to my site are referred by random Google Image Search (images.google.com) queries, this mix of hits might actually partially represent a statistically random sample, combined with the people who know me.
- One wonders, who are those 53% of people who still use IE?
- Mac OS X at 11.5% is a pretty strong showing.
- So much for Linux on the desktop. (0.85%?)
Search engine keyword hits:
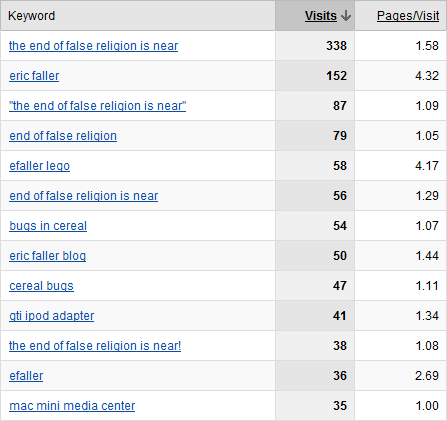
Thoughts:
- It's nice to see that Jehovah's Witness propaganda is still 2x more popular than me (and, alas, the end of false religion still has not come).
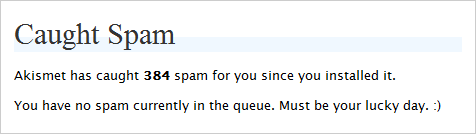
Spam comments
My WordPress spam filter has caught 384 spam comments as of today.
Am I weird because I saw that and immediately thought "Ooh, 384 is a nice round number: 256 + 128!"? (110000000 binary)
This week in Google
I'm always amused by the things people type into Google and find this site with. Here are some from this week:
- seattle yuppie - Apparently I am the #1 search result for "seattle yuppie" (why.. why?).
- are windshield dings covered by insurance - Woo, #1 again. <Your windshield repair ad here, only $500!>
- bomb threats advice - My advice: don't search Google for random blogs if you get a bomb threat!
- fend off mummies - I usually go with a shotgun.
- how to be a tree faller in washington - This one should put to rest the accusations that my name is not a "real" profession. 😛
- disable safety belts golf - Uhh why are people searching for this??
- bugs in cereal - For some reason this one gets a lot of hits, which is scary.
- is religions end near - Not any time soon, but I see that the end of punctuation apparently is.
Weird Google searches
So, after 3 months of running Google Analytics I've had 1174 visits and 2050 page views for a total of 1.75 pages/visit (this doesn't count RSS hits).
The things I find most interesting are the 497 different Google queries that have led people to my site. It's good to see that my name and variations on it are the top hits, but there's quite a "Long Tail" of other random Google searches. Most of them have something to do with my previous posts, but some of them are completely random queries that happened to hit words from multiple different posts (and comments). Here are some of my favorites:
- defeating evil genies
- sugar momma w4m
- how to build knd weapon
- lego store in stanford mall
- how to build a lego ipod case
- pcb designer blog
- most difficult lego kit
- faller car system video
- fixing jetta airbags
- loyalty and membership card programming
Here's the full list: link
Google Analytics
I've been trying out Google Analytics, and so far it's pretty cool. It's geared toward webmasters who are trying to increase their AdWords/AdSense revenue, so there is a lot of stuff that doesn't apply to a small personal web site, but there are still some things I find useful. Currently it's a free service, and it's not even marked 'Beta' (I guess Google expects that the increased AdSense revenue will cause it to pay for itself).
You just have to stick a small tag of javascript in your page template, and you get all kinds of cool stats about your pages. It tracks the basic things like visits & pageviews, but also does more advanced things like plotting the search engine keywords people use to find your site, or their locations on a map of the earth. Here are a couple of screenshots after it had been running on this site for a couple of days:
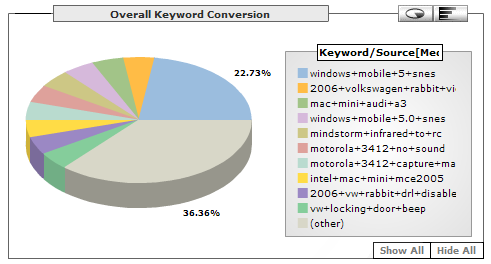
Search keywords
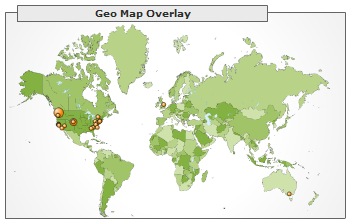
Visitor location map
One downside (at least for a blog) is that it can't track visitors who read your site using RSS readers, since the RSS content doesn't contain the Analytics tracker tag and RSS readers usually don't run embedded javascript anyway. So I mostly find it useful for seeing which Google keywords people are using to find my site.
Google stats
As I mentioned in a previous post, one of my goals for this web site was to be the #1 Google result for a search for my name. As of yesterday (June 26th 2006), this site had been around for little under a month and I had captured the #3 spot, even beating out the other Eric Faller who owns http://www.ericfaller.com/. The #1 and #2 spots were still being held by the GameDev club at the University of Colorado. Ironically, I created those pages while back in college and now I can't get rid of them (grr).
Yesterday Microsoft posted a Scoble video of my coworker Savraj and me explaining what we work on all day. Within one day, that page shot to the #1 spot on Google for a search for my name (#2 for Savraj). Less than 1 day for the #1 spot! I was very surprised. Unfortunately that page already seems to have been linked by a lot of other bloggers, so it will probably be very difficult for me to beat it any time soon.
The video isn't that bad, but unfortunately I had a very bad haircut when it was shot, and I and do a poor job of speaking clearly to the camera. I also manage to screw up one demo 4 times in a row, after I had just said something like "Oh yeah, I do this all the time" :). If you are interested in checking out my office and seeing what I do all day, check out the video. (Yes I realize that if I link to it too, that will only make it worse)
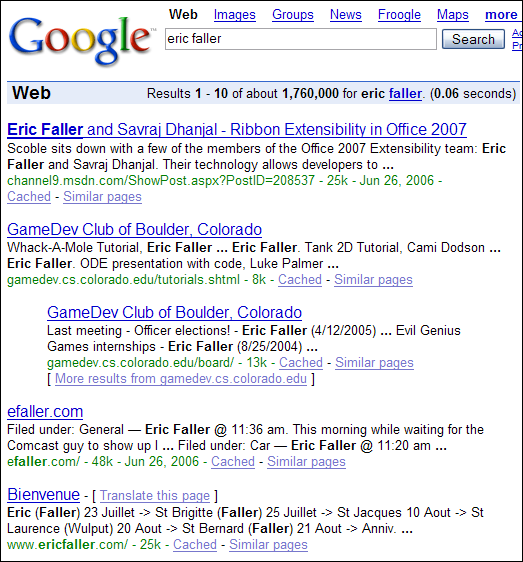
Google results as of June 27th 2006
Welcome
Hello, and welcome to this blog. Introductory posts are always a bit awkward, so as an attempt to take the easy way out I decided to structure this one as a FAQ.
Who are you?
I’m a computer programmer living in the Seattle area.
Why did you create this blog?
For a couple of reasons:
1. I was dissatisfied with the current Google results if you search for my name.
2. I figured I would be able to post some stuff that people might find interesting.
As for reason #1, here’s a link so you can track my progress: Google results for ‘Eric Faller’. As of the date this was written (May 2006), the results include a mishmash of random things:
- The horribly out-of-date homepage for a club I used to run while in college.
- An old friend’s web site for a computer game we used to work on.
- Various other web pages dealing with old school projects.
- The web site of a French dude with the same name as mine (rapidly gaining on the #1 spot).
Fortunately none of the results contain anything too embarrassing, so I’m currently more or less OK. But, I’m fully aware that the first thing that modern people do when meeting (or dating) somebody new is Google them. So, obviously it can’t hurt to have some sort of positive influence over the results. Plus, I have found that reading the archived posts of somebody’s blog is a good way to quickly learn a lot about the person and avoid potentially dangerous conversation topics (“ooh, well when I made that comment about people from the East Coast, I meant everybody except people from New York, you see...”).
As for reason #2, it will be up to you to decide if my posts are actually interesting. I’ve read a good number of blogs so I hope I know what to do. I’ll try to avoid posting boring stuff (“Today I ate cheerios for breakfast, went to work, came home and went to bed”), cryptic stuff (“Here’s a picture of the back of Joe’s head,” (no explanation of who Joe is)), pompous stuff (“Obviously the opening brace goes on its own line – anybody who thinks otherwise is an idiot”), and lazy stuff (“Does anybody know what the website for the IRS is? Post a comment if you know”). My goal is to post more-or-less regularly on a variety of topics, while keeping the content interesting (so far I have learned that pictures = good, and spell checking = good). We’ll see how it goes. If you see a post that sucks, write a comment that says “This post sucks” and I’ll get on it (obviously, more constructive feedback helps as well).
So basically this is all about you and your ego, isn’t it?
Yep, pretty much. Isn’t that the whole idea behind blogging? 🙂
It looks like this blog is running on WordPress?
I looked at a variety of blog hosts/software packages and ultimately chose this one for a couple of reasons:
- It’s free, and there are no ads (always good).
- The provider can easily be switched - don’t have to worry about it getting bought out by some megacorp.
- It’s totally customizable: I can set the style to whatever I want, get rid of any annoying “Powered by Blah Inc” thingies, and if I wanted to it’s easy to write a little PHP widget for the sidebar that shows the weather in Turkey (for example).
You know, Real Programmers write their own blog software by hand. In frickin’ assembly.
Yeah, I know. I started out by mocking up something in ASP.NET, but as I was attempting to write an RSS library by hand, I thought to myself, “NIH syndrome!” and gave up. It probably would have taken a few weeks or months (of my spare time) to implement half the features that every other software package already has, and I realized that all that time could be better spent doing something fun. So that’s the story: basically, I’m lazy.
What's that picture at the top?
That's a picture of my desk. I couldn't think of anything better. Plus, it's a pretty hot-looking desk.
I had some other questions too, but I forgot what they were since you talk so much.
Sorry about that. If you have any questions or suggestions for posts, feel free to leave comments!
- Eric
Me

Apps


Search
Archives
- July 2013
- May 2013
- April 2013
- March 2013
- February 2013
- January 2013
- December 2012
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- September 2011
- August 2011
- July 2011
- June 2011
- May 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- March 2010
- February 2010
- January 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- June 2009
- May 2009
- April 2009
- March 2009
- February 2009
- January 2009
- December 2008
- November 2008
- October 2008
- September 2008
- August 2008
- July 2008
- June 2008
- May 2008
- April 2008
- March 2008
- February 2008
- January 2008
- December 2007
- October 2007
- September 2007
- August 2007
- July 2007
- June 2007
- May 2007
- April 2007
- March 2007
- February 2007
- January 2007
- December 2006
- November 2006
- October 2006
- September 2006
- August 2006
- July 2006
- June 2006
- May 2006